Analyzing a Sample of Strava Data on the Boston Marathon
You know you’ve reached peak Ph.D. thesis avoidance when you decide that scraping 1000+ Strava activities from the Boston Marathon seems like a totally reasonable use of your time. But here we are.
Instead of writing about my actual research, I was wondering what kind of gear folks wear at the Boston Marathon and whether you could see some correlations with their Relative Exertion and finishing times.
The Strava API didn’t prove to be very generous, so I built a little web scraper. I love web scraping, it’s a bit like solving a little sudoku, and every website holds some new challenges.
Step 1: Finding the Segment
The first half of the Boston Marathon course exists as Segment 12666537 on Strava. I did not go for a longer segment, since some people might choose to end their activity early or so. I will, of course, also miss folks who don’t start their watch right at the start or whose watches have GPS glitches. However, for 2025, around 6,000 segment times were recorded on this approximately 21km segment.
Seeing full Strava segment lists requires you to be a summit user, so I had to log into my account. Also, it’s a dynamic website. So, I ended up using selenium for data acquisition.
Show the code
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport pandas as pdimport randomimport timeimport re# opens a Firefox windowdriver = webdriver.Firefox()# Navigate to the websitedriver.get("https://www.strava.com/segments/12666537?filter=overall") ## go through log in procedure manually in the browser and select segment efforts for 2025
Step 2: Collecting Activity URLs
First, I needed to gather all the activity URLs. The segment leaderboard is paginated, so I wrote a loop to click through pages and collect links. I added random delays because I’m not a monster and the website had some latency (the latter could have also been achieved – and made more robust – by asking selenium to wait until the website was done building).
Show the code
activity_urls = []def get_links(): specific_links = driver.find_elements(By.CSS_SELECTOR, ".track-click:nth-child(3) a") specific_urls = [link.get_attribute("href") for link in specific_links]return specific_urlsi =0while TRUE: activity_urls.append(get_links()) time.sleep(random.uniform(5, 10))next= driver.find_element(By.CSS_SELECTOR, ".next_page a")next.click()temp = pd.DataFrame({'url': activity_url_list})temp.to_csv("files/boston_m_urls_2025.csv")
Step 3: Scraping Individual Activities
This is where things got interesting (read: tedious). For each activity URL, I needed to:
Navigate to the activity
Click on the “Overview” tab
Extract stats (distance, pace, time)
Grab device and shoe information
Not get blocked by Strava (hence the generous random delays)
My first attempt had some retry logic for when elements didn’t load properly (the site proved to be fairly sketchy and unstable):
Show the code
for url in current_urls: time.sleep(random.uniform(20, 60)) driver.get(url) time.sleep(random.uniform(2, 9)) overview = driver.find_element(By.LINK_TEXT, "Overview") max_attempts =4 attempts =0 stats = [''] gear = ['']while attempts < max_attempts and (len(stats[0]) <1orlen(gear[0]) <1): overview.click() time.sleep(random.uniform(2, 10)) stats = driver.find_elements(By.CSS_SELECTOR, ".inline-stats") stats = [element.text for element in stats] gear = driver.find_elements(By.CSS_SELECTOR, ".device-section") gear = [element.text for element in gear] attempts +=1 date = driver.find_elements(By.CSS_SELECTOR, "time") date = [element.text for element in date] temp = pd.DataFrame({'date': date[0],'run_data': stats,'gear': gear }) result = pd.concat([result, temp], ignore_index=True)
Eventually, I refined my approach to directly construct the overview URL using a RegEx which stabilized things. I hit a couple of runtime errors, so in the end I stopped my collection after getting the ~1000 runners who had finished the first half Strava segment fastest:
Show the code
for url in current_urls: time.sleep(random.uniform(3, 10)) driver.get(url) time.sleep(random.uniform(2, 9)) current_url = driver.current_url new_url = re.sub(r'segments.*', 'overview', current_url)if new_url == current_url: new_url = re.sub(r'#.*', '/overview', current_url) driver.get(new_url) time.sleep(random.uniform(2, 5)) stats = driver.find_elements(By.CSS_SELECTOR, ".inline-stats") stats = [element.text for element in stats] gear = driver.find_elements(By.CSS_SELECTOR, ".device-section") gear = [element.text for element in gear] date = driver.find_elements(By.CSS_SELECTOR, "time") date = [element.text for element in date] temp = pd.DataFrame({'date': date[0],'run_data': stats,'gear': gear,'url' : new_url }) result = pd.concat([result, temp], ignore_index=True)result.to_csv("files/strava_results.csv")
After several hours of watching Firefox windows open and close (JK, I read a book, the computer was fine on its own), I had my data.
Step 4: The Fun Part – Data Cleaning in R
With raw data in hand, I switched to R for cleaning and analysis. This involved a lot of string manipulation to extract meaningful information from the messy scraped text. The data looked like this:
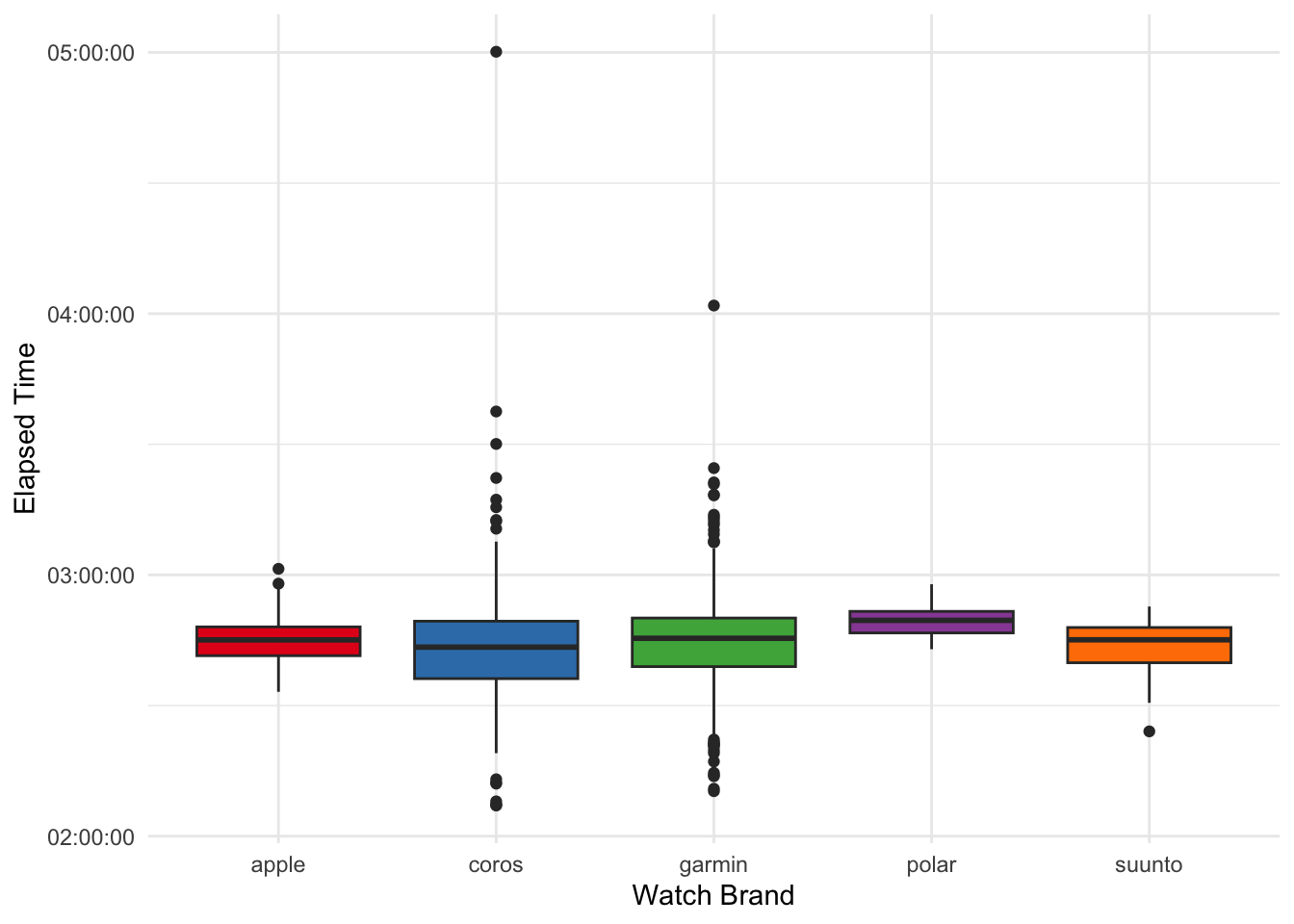
First, I wanted to know what kinds of watches people used. This data is fairly clean since they come straight from the API and, as of lately, Strava by default shows the manufacturer and model. There are of course many varieties of watches, thus I aimed to reduce them to manufacturer and model category (e.g., “Garmin Forerunner” instead of “Garmin Forerunner 265 Music”).
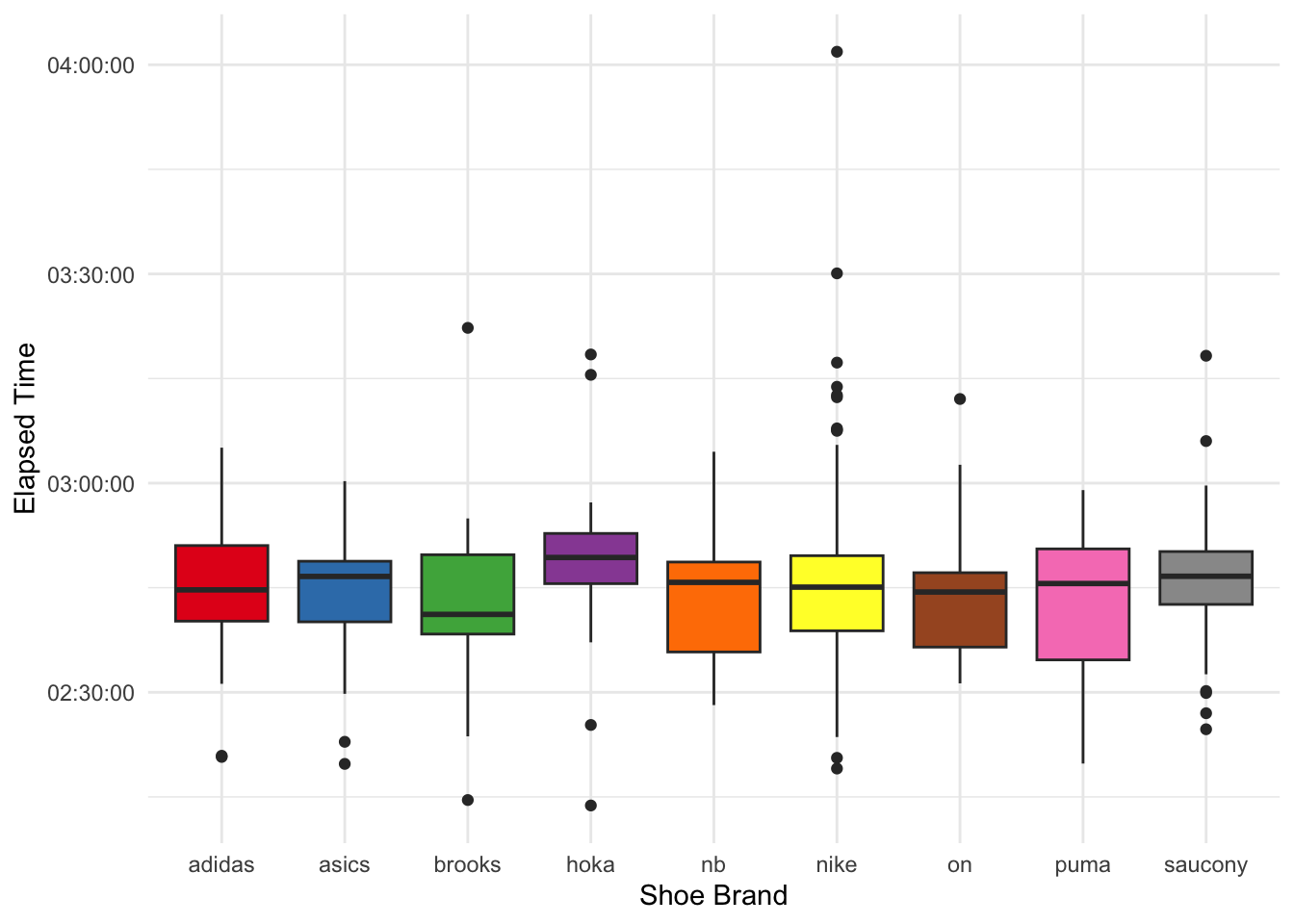
And of course, the shoes – because runners care about shoes almost as much as their splits. Here, the data are manually entered by each user and, thus, messy. However, since you are forced to choose the brand from a drop down menu, at least this part is clean.
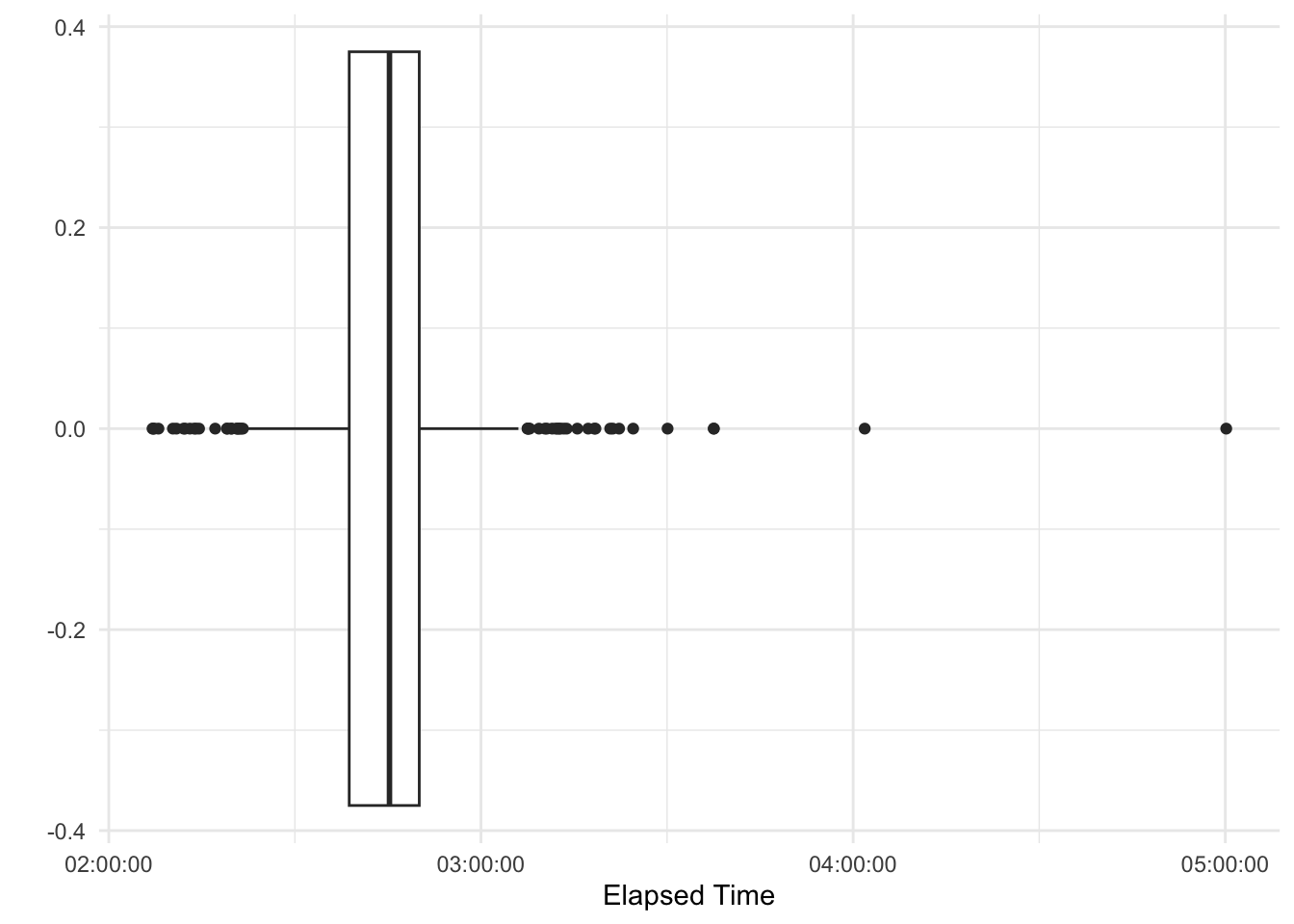
The folks I scraped where quite fast, median elapsed time was around 2:45 hours. However, there are four outliers that started very fast but paid for it eventually. Also, the Boston Marathon qualifying times lie at around 3:30h (depending on age and gender), so we are dealing with a very fit sub-sample here.
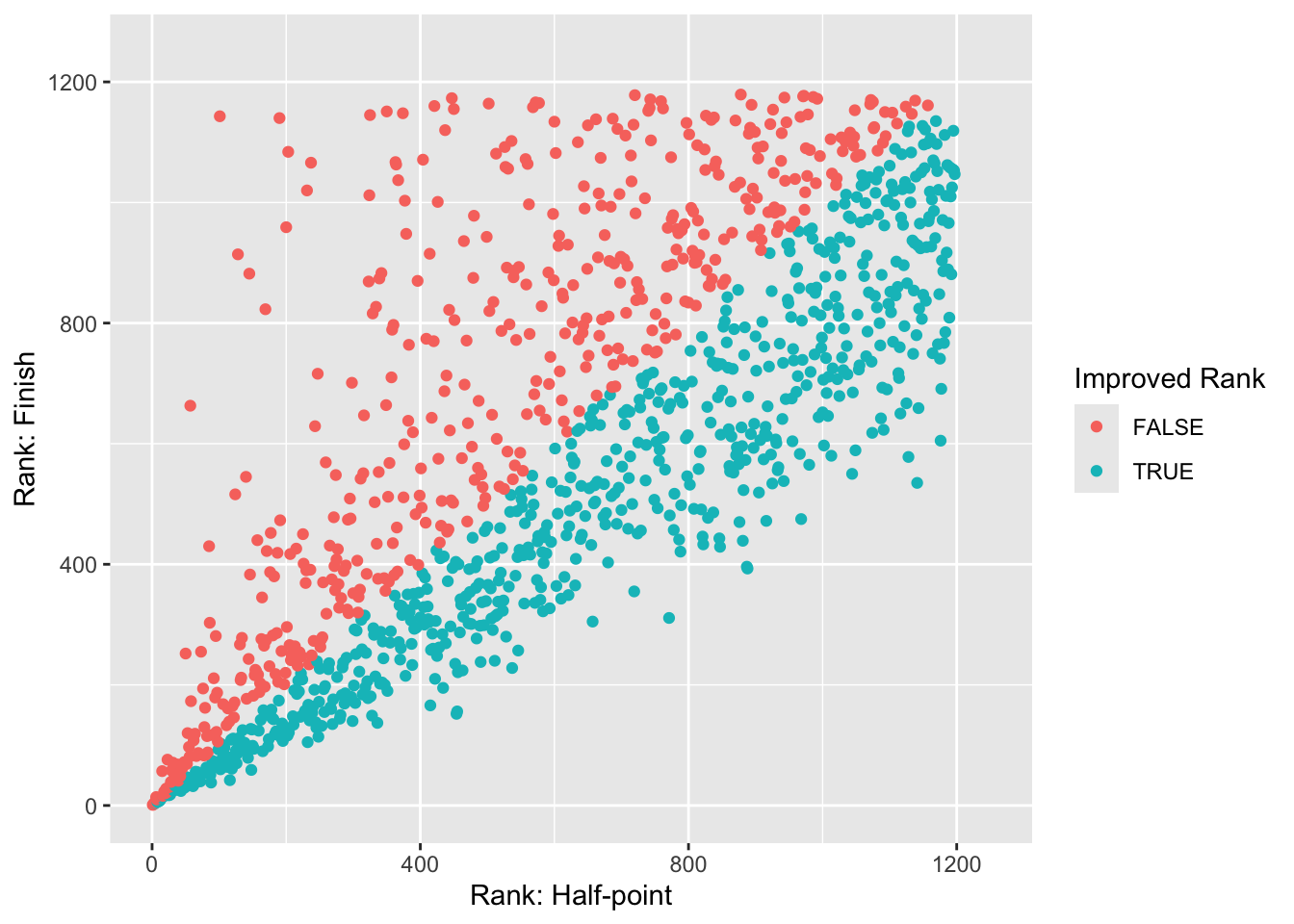
Most runners who started strong also finished strong. The following graphs plots their rank in the segment (i.e., their position in the field at the halfway point) and the final rank in the elapsed time (I did not scrape the exact segment time). However, some of them dearly paid for it.
We see that some folks really came apart badly (the red dots that are low on the x axis but high on the y axis). On the other hand, people who made up ground did only modestly do so – this makes sense, it’s easier to stand still and get passed by 100s of runners than to pass 100s of runners.
However, let’s focus on their gear now.
Popularity
First of all, which shoes are the most popular in my sample (note: you can hover over the bars to get the precise number)? Strava also gave me the mileage of the shoe. IIRC, running shoes should typically be replaced every 400-800km. Hence, I remove every shoe that’s allegedly been used for more than 1,000 kilometers, presuming that the user did not properly enter the correct shoe they ran in.
Show the code
needs(plotly)shoe_cat <- cleaned_data |>add_count(shoe_brand, name ="n") |>drop_na(shoe_brand) |>ggplot(aes(shoe_brand, fill = shoe_brand, text =str_glue("{shoe_brand}, N={n}"))) +geom_bar() +scale_fill_manual(values =c( RColorBrewer::brewer.pal(9, "Set1") )) +theme_minimal() +labs(x ="Shoe Brand", y ="N", caption ="Brands with n<=5 were excluded.") +theme(legend.position ="none")shoe_cat |>ggplotly(tooltip ="text")
Nike clearly dominates here.
Can we see trends with regard to the particular models? The shoe data is messy, so my regexes don’t cut it. However, I can employ a local LLM to clean it up. The prompt I use is:
You are a running shoe expert trying to categorize running shoes. INSTRUCTIONS: extract the running shoe model from the running shoe entry. Try to keep it broad, but with enough detail. Examples: - ‘ASICS Metaspeed Sky 4’ should become ‘Metaspeed’ - ‘Adidas Adizero Adios Pro Evo 1’ should become ‘Adios Pro’ - ‘Nike Vaporfly Next% 3 - 2’ should become ‘Vaporfly’
This gives me an idea of the models but not necessarily the generation, specific colorway, etc. The LLM does an okay job at cleaning, but I still need to clean some things up with a set of regexes. A larger lookup table with different models would probably be a more efficient way of cleaning up these data.
Show the code
needs(ollamar, ellmer)ollamar::pull("qwen2.5:7b")shoe_model <-type_object(model =type_string("extracted model"))ref_prompt_structured <-"You are a running shoe expert trying to categorize running shoes. INSTRUCTIONS: extract the running shoe model from the running shoe entry. Try to keep it broad, but with enough detail. Examples: 'ASICS Metaspeed Sky 4' should become 'Metaspeed'; 'Adidas Adizero Adios Pro Evo 1' should become 'Adios Pro'; 'Nike Vaporfly Next% 3 - 2' should become 'Vaporfly'"shoe_classifier <-chat_ollama(model ="qwen2.5:7b",system_prompt = ref_prompt_structured,params =params(temperature =0.2, # low for consistencyseed =42# Reproducible results ))model_classification <- boston_data |>select(rank, shoes) |>mutate(shoe_km = shoes |>str_extract("\\([0-9,\\.]* km\\)") |>str_remove_all("[(),km]") |>parse_double(),shoe_brand = shoes |>str_remove(r"(Shoes: )") |>str_remove(" \\([0-9].*$") |>str_to_lower() |>str_replace_all("new balance", "nb") |>str_extract("^[a-z]*"),shoe_model = shoes |>str_remove(r"(Shoes: )") |>str_remove(" \\([0-9].*$") |>str_to_lower() |>str_replace_all("new balance", "nb") |>str_remove("^[a-z]*") |>str_squish() ) |>filter(!str_length(shoe_brand) ==0) |>filter(shoe_km <1000) |> dplyr::pull(shoe_model) |>enframe(name =NULL, value ="x") |>rowid_to_column("id") |>pmap( \(x, id) {if ((id -1) %%20==0) { classifier <<-chat_ollama(model ="qwen2.5:7b",system_prompt = ref_prompt_structured,params =params(temperature =0.2,seed =42 ) ) } classifier$chat_structured(x, type = shoe_model) },.progress =TRUE )models <- model_classification |>bind_rows() |>mutate(model =str_to_lower(model) |>str_remove_all("[0-9]|next%|adizero|zoomx|air zoom") |>str_squish() |>str_replace_all(c("alpha fly"="alphafly","fast.?r.*"="fast-r","alphafly.*"="alphafly","a fly"="alphafly","^alpha$"="alphafly","meta.?speed.*"="metaspeed","^af.*$"="alphafly","alphaphly"="alphafly","cloud.?boom .*"="cloudboom","^pro$"="adios pro","adios pro evo"="adios pro","vaporfly.*"="vaporfly","hype elite"="hyperion elite","cielo x.*"="cielo","rocket x.*"="rocket","sc"="supercomp","fuelcell supercomp"="supercomp","feulcell supercomp"="supercomp","fuelcell rc"="supercomp","nike "="","vapor$"="vaporfly","vf.*"="vaporfly","deviate.*"="deviate","endorphin.*"="endorphin","^alpha s$"="alphafly"," v$"="") ))boston_data |>select(rank, shoes) |>mutate(shoe_km = shoes |>str_extract("\\([0-9,\\.]* km\\)") |>str_remove_all("[(),km]") |>parse_double(),shoe_brand = shoes |>str_remove(r"(Shoes: )") |>str_remove(" \\([0-9].*$") |>str_to_lower() |>str_replace_all("new balance", "nb") |>str_extract("^[a-z]*"),shoe_model = shoes |>str_remove(r"(Shoes: )") |>str_remove(" \\([0-9].*$") |>str_to_lower() |>str_replace_all("new balance", "nb") |>str_remove("^[a-z]*") |>str_squish() ) |>filter(!str_length(shoe_brand) ==0) |>filter(shoe_km <1000) |>bind_cols(models)
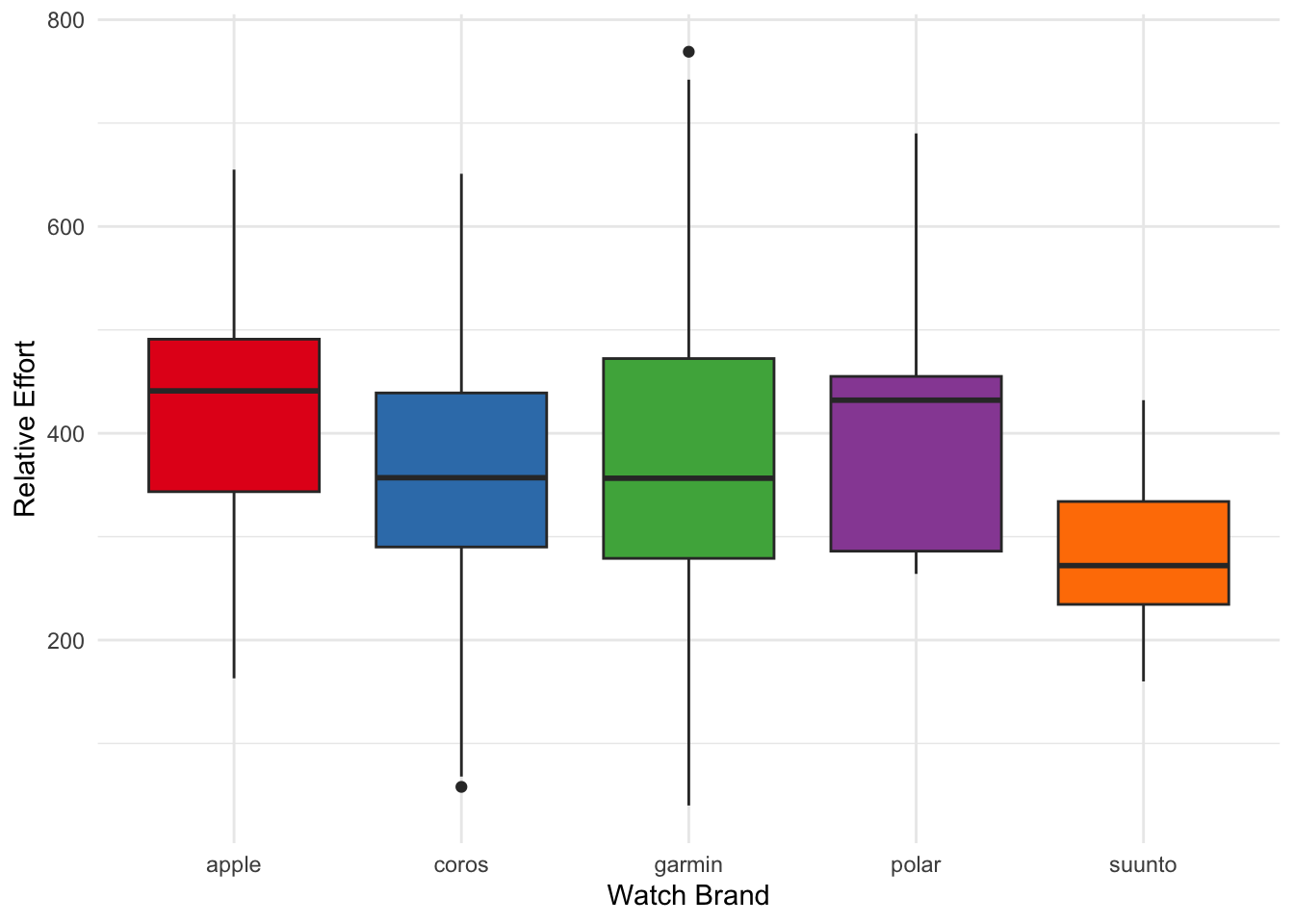
Here, it is worth noting that some brands were hardly present in the sample (i.e., Polar, Suunto). However, it appears as though faster runners tend to have dedicated running watches (i.e., not an Apple Watch).
Let’s delve a bit deeper into the Garmin Forerunner universe. Upon first glance when I checked the data, it seemed as though faster runners tended to have worse watches. Is this true?
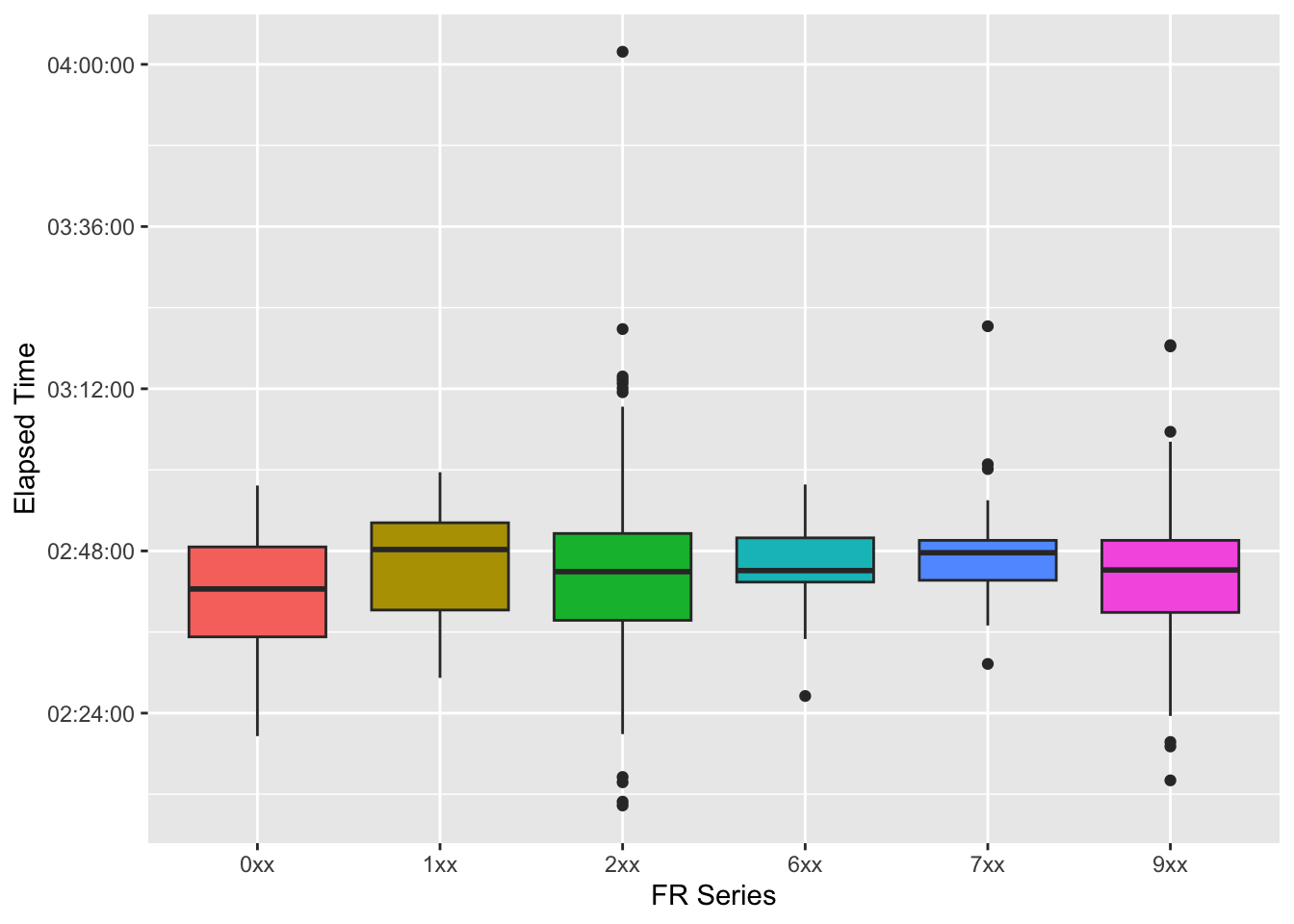
The 2XX models are definitely the most popular, followed by the flagship 9XX series. It’s worth noting that the 245 was released in 2019, whereas the 965 was released in 2023 (and is still the latest Forerunner model). Maybe some fast runners have just been running for a long time and not changed their watch?
Now we can plot the times. To simplify the plot, I just use the first number of the series (starting with 0 for the most affordable series):
It seems as though the really fast runners tend to wear 2XX and 9XX. However, people who wear the most affordable watches have the fastest median times in the graph. But these are of course mere tendencies.
Relative Effort
Finally, let’s look at Relative Effort (RE). Generally speaking, it is a score that depends on the time you spent in particular heart rate zones. Higher scores imply that the runner spent more time in higher heart rate zones. However, according to Strava, the Perceived Exertion (which a runner can enter manually) also affects RE, making it a quite unreliable measure.
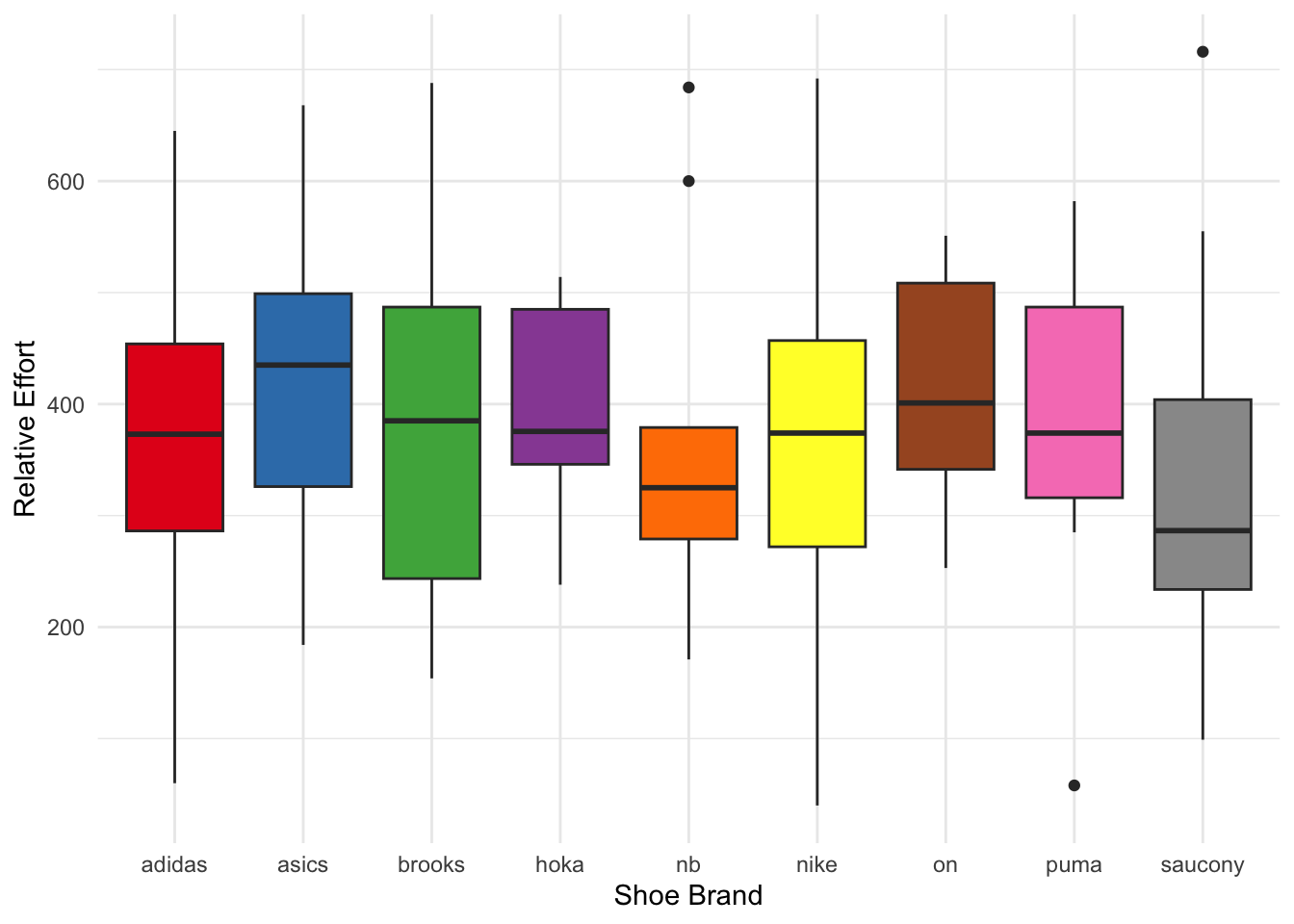
Perhaps, some shoes are bouncier and thus lead to less cardiovascular work, resulting in a lower relative effort?
We see that RE values are all over the map, this might be due to people setting their heart rate zones incorrectly, rating their efforts as 10/10 in terms of perceived exertion, or really just suffering like dogs. But let’s for now just assume that RE is a good measure and not biased by user input.
Another factor would be running watches that measure heart rate inaccurately.
Here, no striking differences emerge (and bear in mind that we are operating on very few data points for some of the brands).
Shoe effects
Let’s finally go after the shoe effect on relative effort – on the brand level. To this end, we can match runners that have similar times but wear different shoes. I use Nike as my reference category and match runners who wear one of the 3 most popular brands (Adidas, Asics, Saucony). Since the overwhelming majority of runners wears Garmin watches, I focus on this group to even out differences in HR sensors.
Show the code
needs(MatchIt)re_shoes <- cleaned_data |>filter(shoe_brand %in%c("nike", "asics", "adidas", "saucony"), watch_brand =="garmin") |>mutate(is_nike =if_else(shoe_brand =="nike", 1, 0),elapsed_time_num =as.numeric(elapsed_time) ) |>rename(distance_run = distance)# Match on elapsed time and watch brandmatch_shoes <-matchit( is_nike ~ elapsed_time_num,data = re_shoes,method ="nearest",distance ="glm",ratio =1,caliper =300# only considering runners that are within 5 minutes=300seconds )
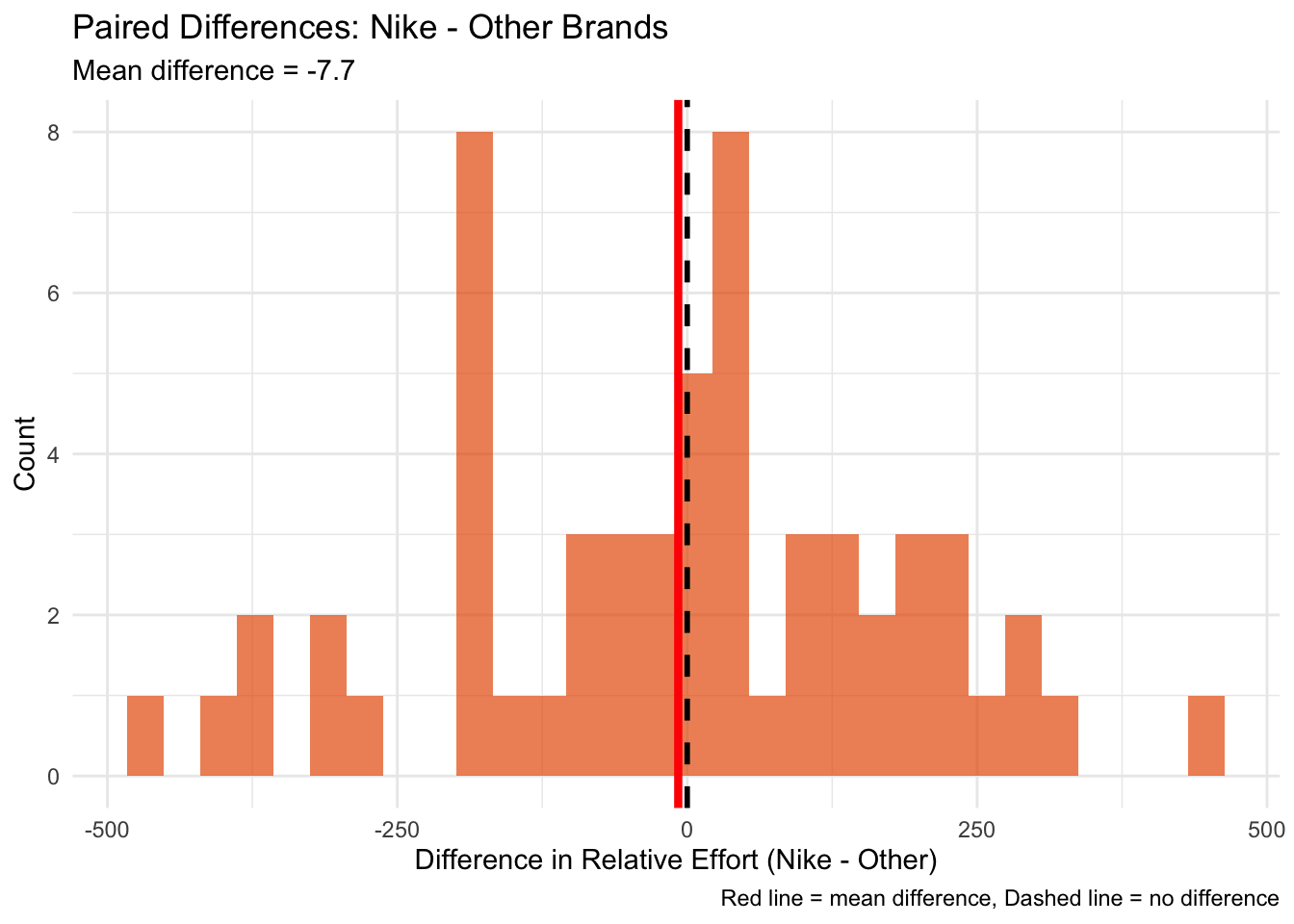
Now the algorithm has paired runners into groups of two people that are similar with regard to their elapsed time and pace and have the same watch. However, only one of them wore Nike shoes, the other one did not. Thus, we have an artificial treatment and control group, if one will. Let’s have a look if there are differences.
Paired t-test
data: matched_pairs$re_1 and matched_pairs$re_0
t = -0.30148, df = 58, p-value = 0.7641
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-59.17431 43.68279
sample estimates:
mean difference
-7.745763
Heck no. The p value tells me that if there truly were no difference between Nike and other brands, we would observe a difference as large as (or larger than) what we saw in about 76% of random samples.
Reflections
What can we take home from this? Garmin dominates the market, it’s not even close. The Forerunner is clearly the most successful among runners. Also, Nike dominates the shoe market. Looking at RE did not produce any insights. Perhaps with more and cleaner data (i.e., same devices, heart rate straps, validated heart rate zones, standardized user input), better comparisons could have been possible. But this would also require Strava opening up about how the algorithm exactly works.